
Recent advances in image clustering typically focus on learning better deep representations. In contrast, we present an orthogonal approach that does not rely on abstract features but instead learns to predict image transformations and directly performs clustering in pixel space. This learning process naturally fits in the gradient-based training of K-means and Gaussian mixture model, without requiring any additional loss or hyper-parameters. It leads us to two new deep transformation-invariant clustering frameworks, which jointly learn prototypes and transformations. More specifically, we use deep learning modules that enable us to resolve invariance to spatial, color and morphological transformations. Our approach is conceptually simple and comes with several advantages, including the possibility to easily adapt the desired invariance to the task and a strong interpretability of both cluster centers and assignments to clusters. We demonstrate that our novel approach yields competitive and highly promising results on standard image clustering benchmarks. Finally, we showcase its robustness and the advantages of its improved interpretability by visualizing clustering results over real photograph collections.
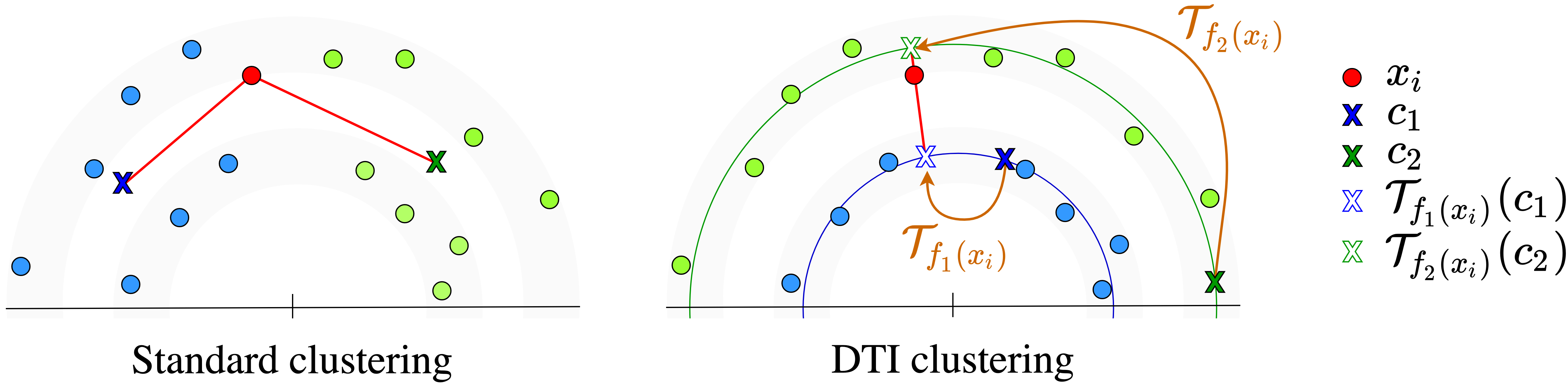
Given a sample and prototypes
and
, standard clustering such as K-means
assigns the sample to the closest prototype. Our DTI clustering first aligns prototypes to the sample using a
family of parametric transformations - here rotations - then picks the prototype whose alignment yields the
smallest distance.
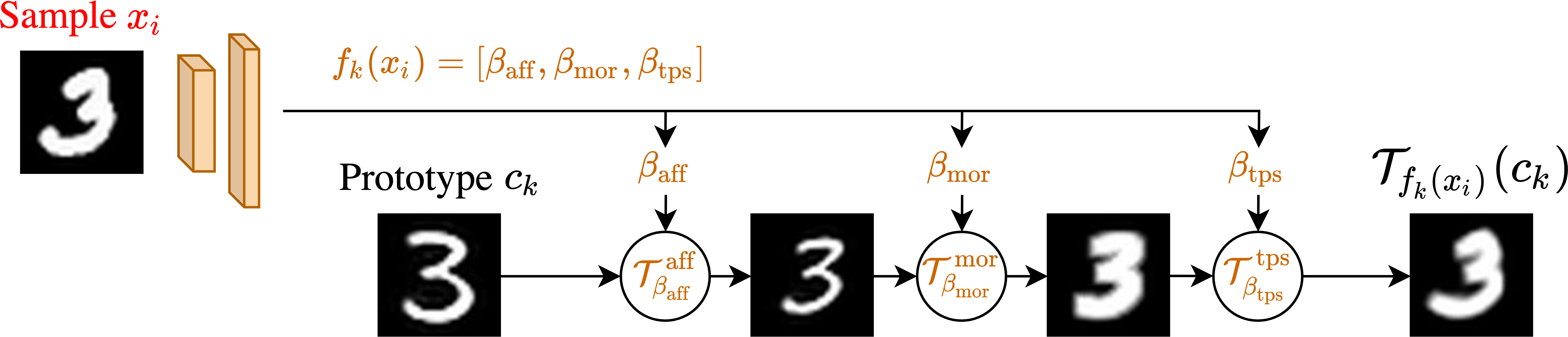
We predict alignment with deep learning. Given an image
, each deep parameter predictor
predicts
parameters for a sequence of transformations - here affine, morphological and thin plate spline transformations -
to align the prototype
to the query image
.


We show the 6 best qualitatives prototypes learned using DTI clustering with 20 clusters for Florence location in MegaDepth dataset. For each cluster, we show the 20 samples leading to minimal reconstruction errors among all the samples in the cluster as well as corresponding transformed prototypes. Note how it manages to model real image transformations like illumination variations and viewpoint changes.

We show the 5 best qualitatives prototypes learned using DTI clustering with 40 clusters for different Instagram photo collections. Each collection corresponds to a large unfiltered set of Instagram images (from 10k to 15k) associated to a particular hashtag. Identifying visual trends or iconic poses in this case is very challenging as most of the images are noise. You can visualize the type of collected images directly in Instagram: #balitemple, #santaphoto, #trevifountain, #weddingkiss, #yogahandstand.



@inproceedings{monnier2020dticlustering,
title={{Deep Transformation-Invariant Clustering}},
author={Monnier, Tom and Groueix, Thibault and Aubry, Mathieu},
booktitle={NeurIPS},
year={2020},
}
This work was supported in part by ANR project EnHerit ANR-17-CE23-0008, project Rapid Tabasco, gifts from Adobe and HPC resources from GENCI-IDRIS (Grant 2020-AD011011697). We thank Bryan Russell, Vladimir Kim, Matthew Fisher, François Darmon, Simon Roburin, David Picard, Michael Ramamonjisoa, Vincent Lepetit, Elliot Vincent, Jean Ponce, William Peebles and Alexei Efros for inspiring discussions and valuable feedback.
© You are welcome to copy this website's code for your personal use, please attribute the source with a link back to this page and remove the analytics code in the header. Possible misspellings: tom monier, tom monnie, tom monie, monniert.